

How Non-Uniform Processing-Element Access (NUPEA) Supports the Most Energy Efficient Processor

Modern computing systems face a fundamental trade-off: achieving extreme energy efficiency often comes at the cost of general-purpose programmability. Today, we're introducing one of our key innovations in the Electron E1 processor that helps reconcile this tension and fix what wastes the most energy in a processor, called Non-Uniform Processing-Element Access (NUPEA). This work was just published at this year's International Symposium on Computer Architecture, our field's top academic conference.
Why NUPEA Is Needed
To understand why NUPEA is needed, it's important to recognize that in modern architectures, data movement—not computation—is the dominant bottleneck for energy, performance, and scalability. Thus, achieving high efficiency is synonymous with keeping the bulk of the computational work as close as possible to the memory that is accessed.
The Limits of NUMA
Today’s systems, including CPUs, GPUs, and other programmable accelerators, address this challenge by using distributed data memories amongst processing elements (PEs) [refer to figure of NUMA]. The idea is to predetermine which program data should be mapped to which memory, as well as how tasks should be assigned to PEs near each corresponding memory. This approach is widely known as Non-Uniform Memory Access (NUMA), as different memories have different (i.e., non-uniform) access times to different processors.
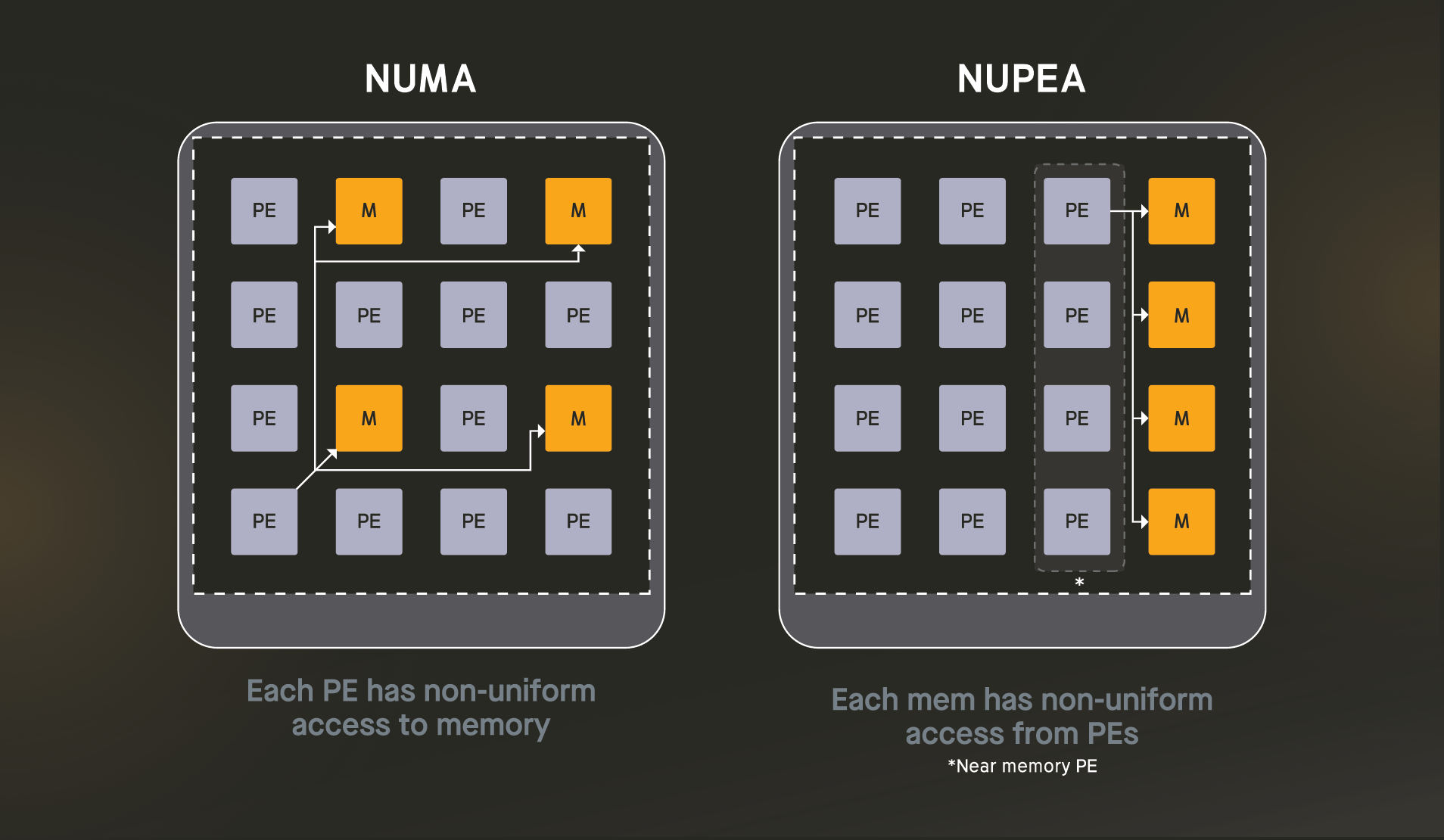
NUMA alone fails to balance efficiency and generality. For all but the most simple programs, determining how to co-schedule data and tasks is a nearly impossible compiler and systems problem. Workloads with irregular computational patterns (e.g., sparse ML models) are too hard to analyze, and even with perfect information it might not be possible to map data to significantly reduce data movement. Another common approach is to shift this burden to the programmer using domain-specific languages or low-level APIs. However, this sacrifices generality and limits usability.
How NUPEA Works
NUPEA is an alternative to NUMA that comes from a simple insight: while analyzing and manipulating data is unduly difficult, analyzing and manipulating instructions is trivial for today’s compilers. Thus, rather than distributing memories, NUPEA instead gives PEs varying proximity to memory [refer now to the figure for NUPEA]. The effect is that some PEs are near-memory – thus more efficient — and other PEs are farther away. Efficient’s effcc Compiler can identify the critical instructions (e.g., that fire most often or are on the critical path) and place them closer to memory, significantly reducing data movement. Other, less critical instructions can be placed further away without a significant effect on energy or performance. Additionally, by limiting the fraction of near-memory PEs, NUPEA architectures can use lightweight, energy-efficient memory access networks.
Benefits of NUPEA
NUPEA is a step toward smarter hardware-software co-design—offering a practical path to energy-efficient, general-purpose computing. In short, NUPEA reduces communication energy by moving the most important instructions to a limited set of near-data PEs. It works without any programmer involvement or profiling, works on any programming language, and does not require the data access pattern to be regular or analyzable – thus simultaneously achieving efficiency and general purpose programmability.
We invite you to explore the full technical details in our paper presented at ISCA here, and stay tuned for more innovations from Efficient.