

General‑Purpose Acceleration at Efficient Computer

Why the Status Quo Falls Short
If you’re building modern software—whether it’s AI inference, real‑time analytics, or slick mobile apps—you’re probably running on two kinds of silicon:
- CPUs: Wonderfully flexible, but they burn energy and time figuring out how to run your code fast.
- Accelerators (GPUs, TPUs, ASICs): Lightning‑quick for the one job they were designed for, but a headache (or impossible) for everything else.
The industry has spent decades bouncing between these extremes, stitching fixed-purpose accelerators next to general‑purpose CPUs and hoping the trade‑offs cancel out. They rarely do:
- Developers juggle multiple toolchains and must carve applications into accelerator‑friendly kernels.
- Architects keep adding accelerator blocks to chase new workloads, bloating die area and power.
- End users still watch their batteries drain or their cloud bills climb.
What if we could have the best of both worlds: accelerator‑class efficiency and CPU‑class programmability?
A Fresh Take: The Fabric Architecture
At Efficient Computer, we stepped back and asked a simple question: Why are accelerators fast? The short answer isn’t exotic math units—it’s that accelerators exploit program structure that CPUs largely ignore. Our Fabric architecture brings the same structural awareness to a general‑purpose processor.
How it Works (in plain English)
- Dataflow at the core. Instead of marching through instructions one by one, the Fabric on the Electron E1 represents your program as a web of tiny tasks that pass data directly to each other. Tasks run the instant their inputs arrive—no global clock‑ticking contest.
- Tiny, tidy memories. Values stay close to the logic that needs them, slashing energy lost to long trips through huge caches.
- No special instructions required. The math units look familiar (adds, multiplies, loads, stores), so any standard language maps cleanly.
Meet The effcc Compiler: Your Friendly Compiler Companion
Of course, most of us don’t want to draw dataflow graphs by hand. The effcc Compiler does the heavy lifting:
- Analyzes program structure (loops, dependencies, data reuse).
- Places tasks on the Fabric mesh for maximum parallelism and locality.
- Generates a binary that runs out‑of‑the‑box—no manual tuning required, but plenty of hooks if you like to tinker.
.png)
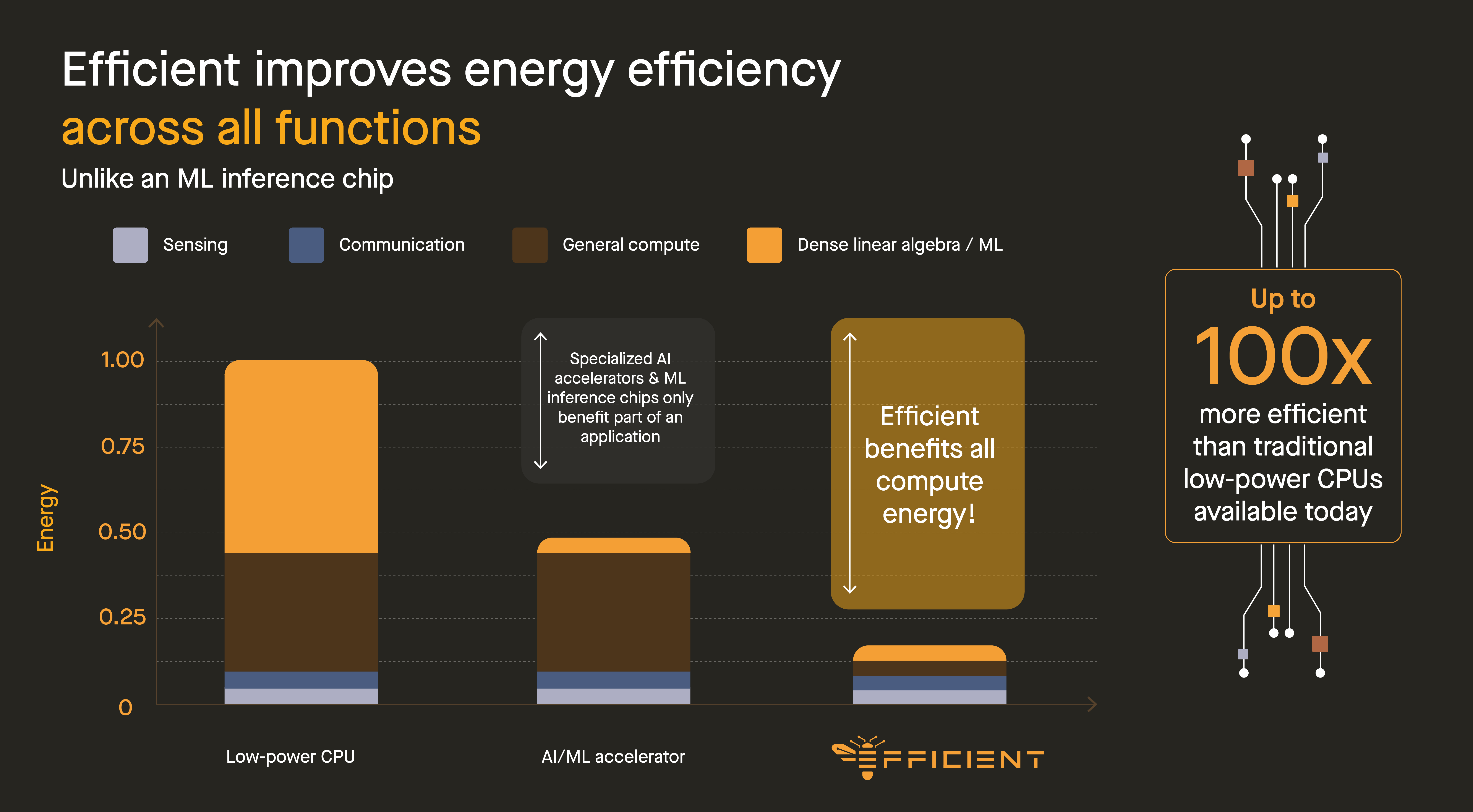
The Payoff: Accelerator‑Class Efficiency for Everything
Because the Fabric runs all parts of your application—not just hand‑picked kernels—it can move the energy‑performance needle on real workloads, end‑to‑end.
What Does That Mean in Practice?
- Longer battery life on devices that can’t afford a farm of accelerators.
- Lower cloud bills because you need fewer servers (and less cooling) for the same job.
- Simpler software stacks—one toolchain, one binary, one happy developer.
Ready to Try It?
- Developers: Contact us for access to our SDK and run your existing C/C++ code through the effcc Compiler—no code changes needed.
- Researchers: Dive into our whitepaper for a deeper architectural tour.
- Hardware partners: Contact us for IP licensing or evaluation kits.
We’re excited to see what you build when efficiency is no longer the enemy of programmability. Join the conversation on Bluesky @efficientcomputer or drop us a note at contact@efficient.computer.