

AI is more than AI: the importance of generality in AI-enabled systems
Everyone is doing AI and to make AI-enabled systems work well, general-purpose computation needs to be fast and efficient; that is what Efficient is all about.
For a long time, when I thought of “AI”, my first intuition was to think of a big blob of dense linear algebra that computes thousands of transformers or convolutions. That was the case as I watched AI first emerge as a basic technology over the last decade or so.
But that is no longer the case: what we have learned first-hand at Efficient is that an AI application is always more than just “AI” in this technological sense. AI has matured, and it is now being integrated into much more complex systems. Real systems, especially ones designed to interact with the physical world, do a lot more than just the dense linear algebra of AI’s youth.
At Efficient, we see a little bit of everything in AI-enabled systems. Customers build applications that are rich with multimodal inputs from a range of sensors, and data sources and these data need to be computationally stitched together (a process called “sensor fusion”). AI models often don’t like raw data, and computation needs to do featurization, format conversion, and scaling. DSP computations show up everywhere, as noisy signals need filtering and fidgeting. And that’s all before data flows into an AI model.
Then AI takes over and runs for a while, churning out insights from raw signals and giving applications their magic. We go from raw audio data to keywords to concepts, or from pixels to text to images to ideas. It really is amazing to see these applications evolve.
But once the magic is over, it’s back to business. You now need to do non-max suppression for your YOLO model. Or your mobile system may need to run its model-predictive control loop again. Or maybe it’s running simultaneous localization and mapping (e.g., visual SLAM), which runs a non-linear optimizer in a loop for a while. Or maybe you’re just doing state estimation for head and eye tracking in a headset, or estimating the state of an industrial machine.
AI is a fundamental part of the application, and it is what has spurred the ongoing renaissance in physical AI applications, led by partners of ours like BrightAI. The value of an end-to-end system, however, is determined by its overall speed and efficiency, including the general-purpose code. If a system only optimizes for the part that does the dense linear algebra in the guts of the AI, then the speed and efficiency bottleneck will be the remaining, general-purpose code.
The concept that the unoptimizable part is the bottleneck is called Amdahl’s Law and it is the most important rule in computer architecture. Amdahl’s Law is the reason that you should not rush out and buy a fixed-function AI chip or NPU if you’re building an AI-enabled physical system. You need hardware that makes your entire application fast and efficient, and an NPU isn’t it.
At Efficient, we like to think about it in terms of the data. Check this out:
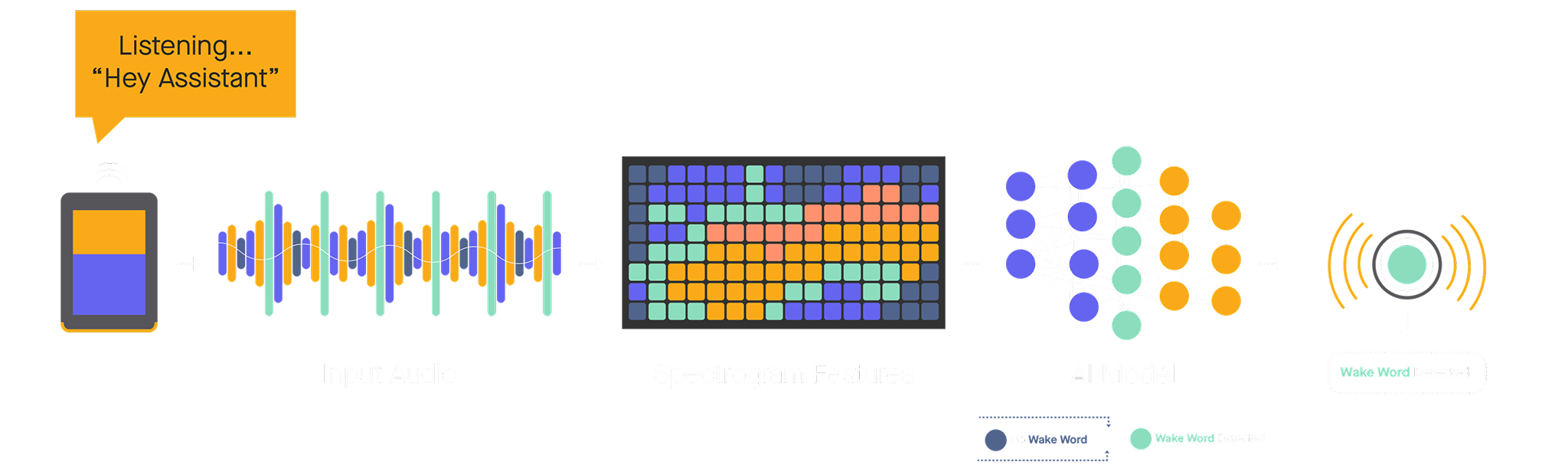
This is a picture of a simple streaming audio application that looks for wake-up words using AI (for those in the know, this is the Streaming Wake Words benchmark from MLPerf Tiny). The input is an audio stream that gets featurized using DSP algorithms and other computations. The features then get passed through a convolutional neural network to figure out if you’re talking to your pet robot.
A fixed-function NPU for the AI part is so tempting: look at that large, complex AI model in the middle of the diagram. Let’s be naive and play victim to Amdahl’s Law. What if you use a popular embedded computing SoC that incorporates an NPU as an AI model accelerator? Now, your AI model is very fast and efficient. Success?
NO! We bought one of several popular Arm U55 NPU-enabled platforms and did some measurements. With the AI model on the NPU, featurization now takes 99% of the time and energy required to run the application. And the NPU doesn’t do a thing for the hodgepodge of other computations besides the AI model, so you’re running those on a legacy CPU while your NPU sits there idle. What’s worse is that you have to pay more to have the NPU sitting there mostly doing nothing alongside the inefficient CPU that you already had. What a waste!
Efficient solves the problem with our general-purpose, energy-efficient Fabric architecture. The Fabric runs the entire application efficiently, including the AI model. We did some measurements on our hardware using the exact same code, not a single line changed. Featurization on the Efficient Fabric uses 67x less energy than the CPU.
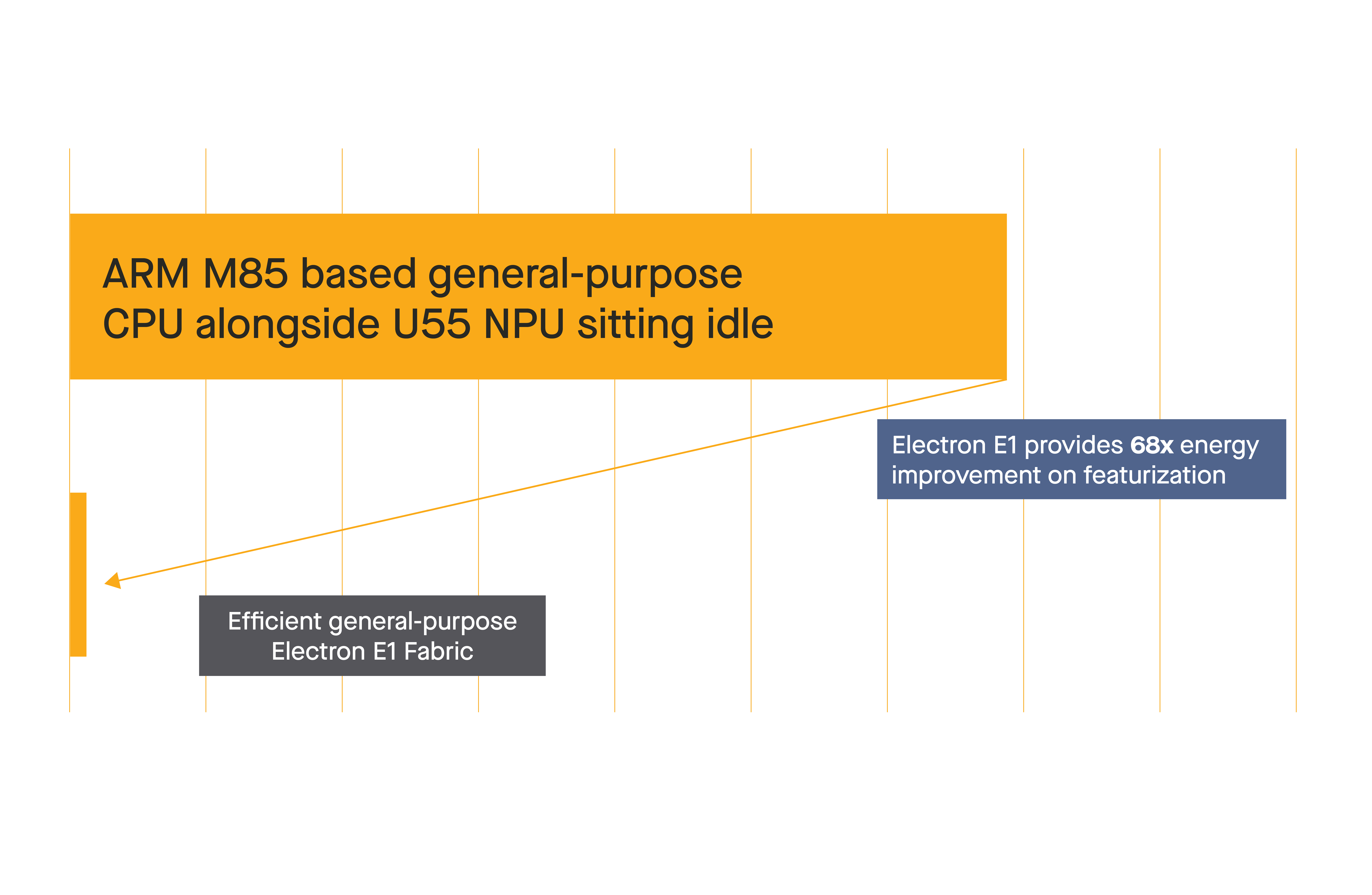
End-to-end, Efficient runs everything including the AI part for 37x less energy and is about 30% faster overall. To put that in context, the competing SoC with the NPU runs streaming audio AI for about 23 hours on a AA battery, while Efficient runs for 35 days.
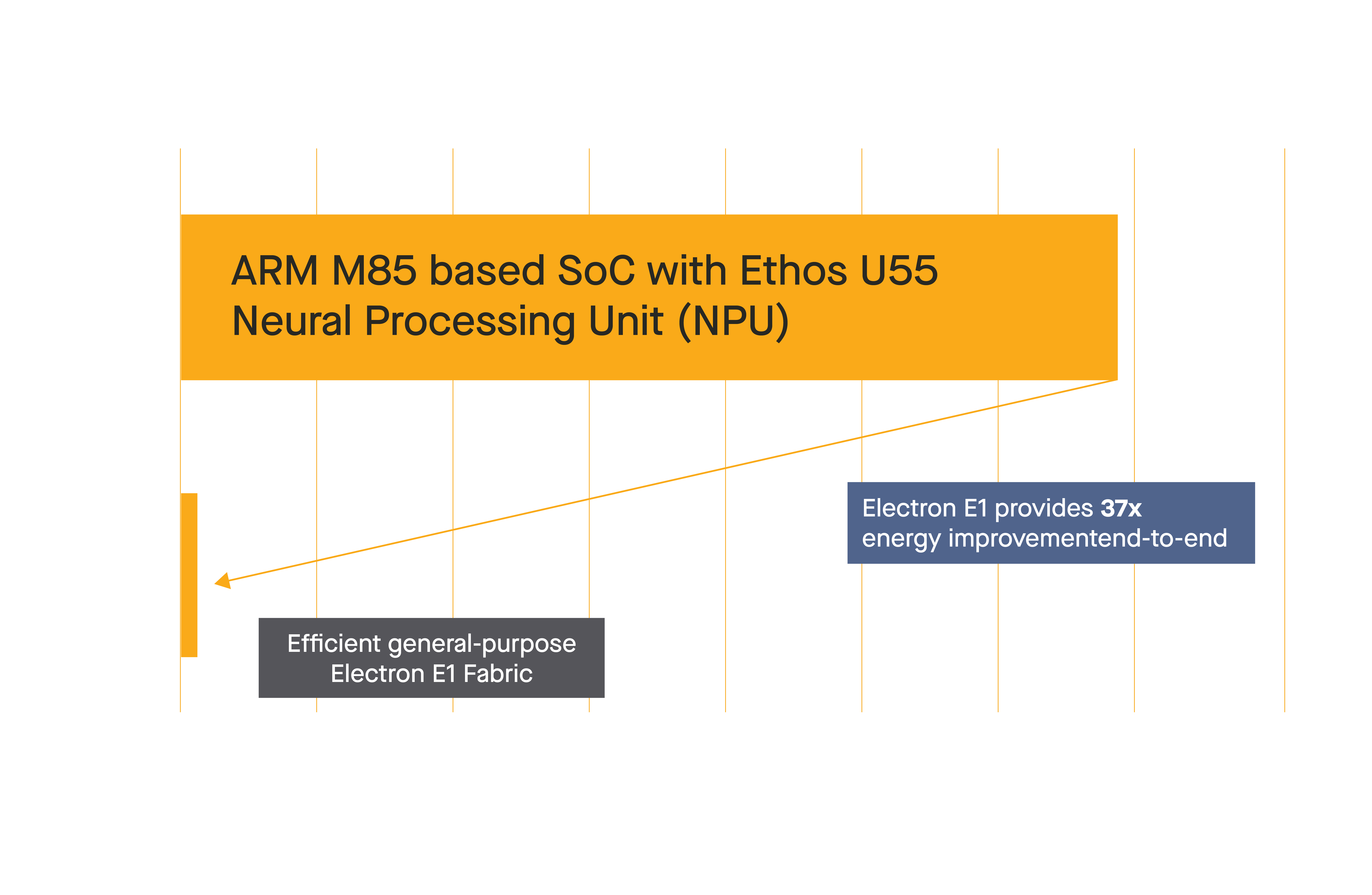
Efficient makes the whole application efficient. Don’t be a victim of the Amdahl’s Law bottleneck created by fixed-function accelerator non-solutions.
AI is more than just AI, and your AI-enabled applications deserve a better architecture that makes all of your code fast and efficient. Efficient’s Electron E1 SoC and its Fabric architecture are available now to help you design your next generation of AI-enabled systems, whether it is physical AI, infrastructure, space, defense, robotics, automotive, wearables, health sensors, or anything else you can dream up. Experience the efficiency. Contact us today at contact@efficient.computer.